
Fundamentos de Ingeniería de Datos
Published:
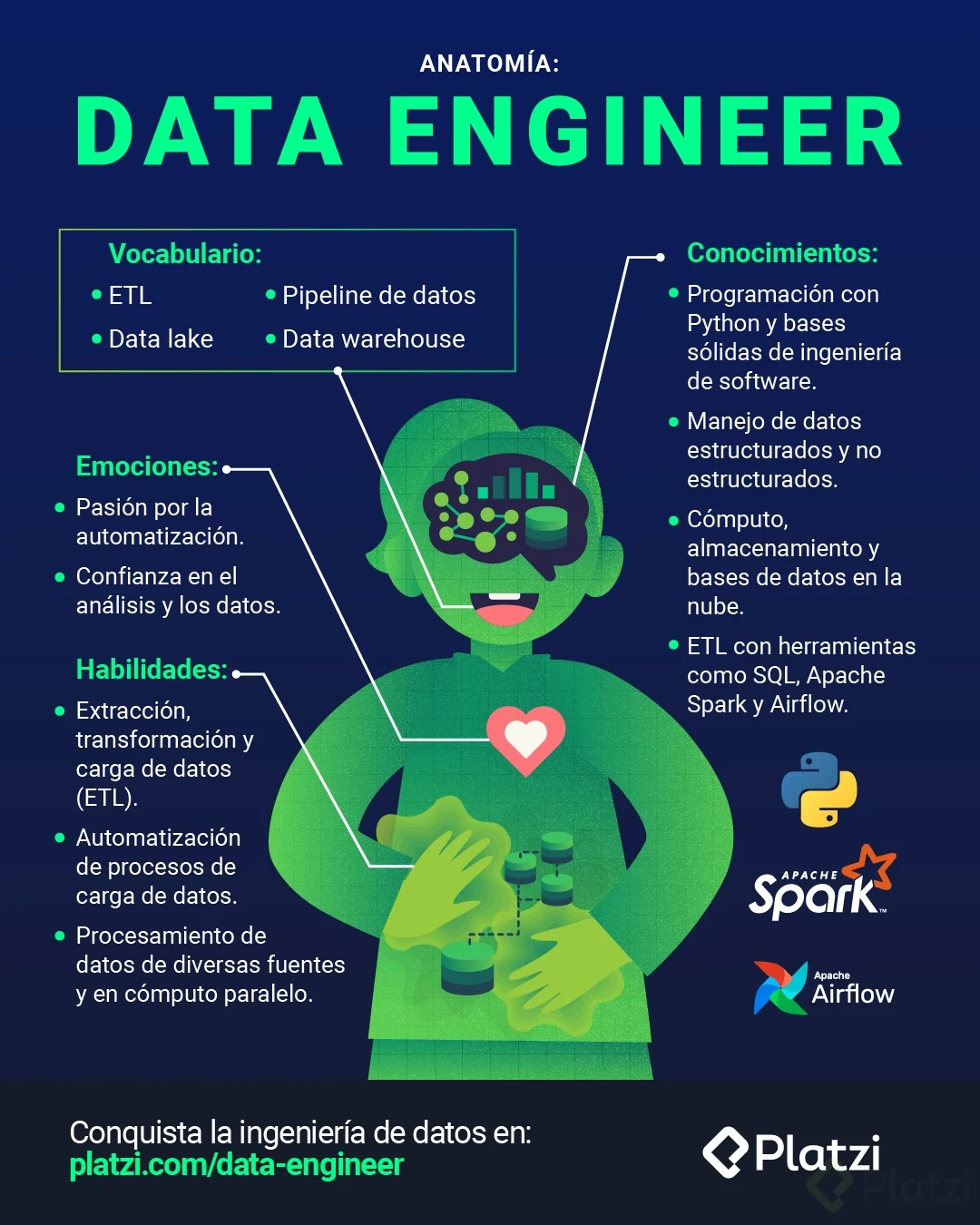
Las y los Data Engineer o Ingenieros de Datos se encargan de tomar los datos crudos de valor, para transformarlos y almacenarlos en bases de datos de analítica y disponibilizarlos a software que funciona en sistemas de producción. Para ello crean pipelines ETL y utilizan bases de datos especializadas, con los que abastecen de datos a los demás roles de un equipo de data y a sistemas de software que funcionan con datos y machine learning.
Intro
Se necesitan conocimientos esenciales de data science e ingeniería de software. Tener bases sólidas de arquitectura e infraestructura de computadoras.
Tareas de un Data Engineer
Data Engineer:
- Diseñar proyecto (código y tablas).
- Recoding en otro lenguaje.
- Evaluación y prueba del modelo.
- Scheduling.
- Monitoreo de features/ características.
- Deployment (CI/CD items, APIs…).
Los componentes ideológicos de un DataOps:
- Agile: esta filosofía busca que cada proyecto genere valor en cada etapa.
- DevOps: operaciones de desarrollo.
- Lean Manufacturing: esta complementa a agile, enfocarnos en los procesos de alto valor, minimizando proceso complejos.
Herramientas del ciclo de DataOps
Agile
Se entregan resultados diferenciales de manera continua. Usa tu criterio, usa lo que te sirve.
Existen dos grandes metodologías:
- Scrum
- Kanban
Scrum
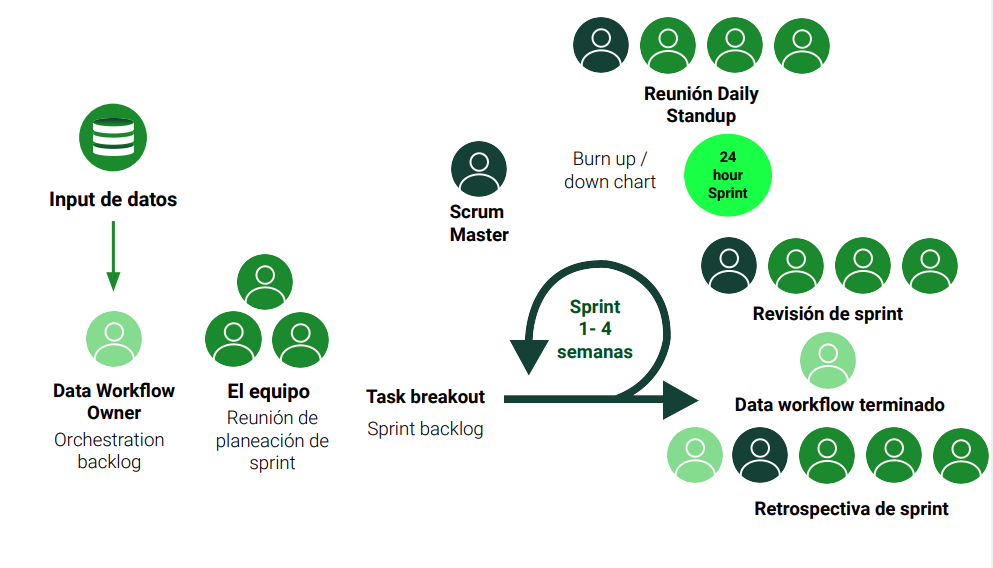
Separa los tiempos de desarrollo en Spints. Cada Sprint se define en la interioridad del equipo de trabajo. Se realizan reuniones de Standup, analizando los resultados del desarrollo. Se reunen los resultados y se analizan para conocer los errores y beneficios.
Kanban
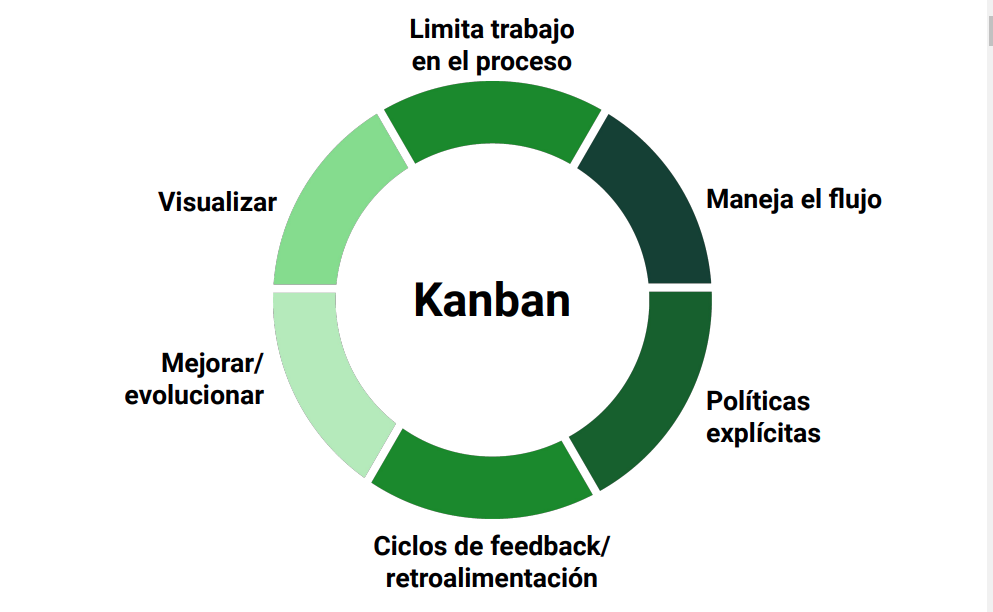
Buscar en ciclos muy cortos contribuciones por tarjetas. Esta tarjetas obedecen a un flujo realista de trabajo, donde se observa lo que hay que hacer, lo que está en proceso y el trabajo futuro. Los ciclos se establecen en la interioridad del equipo de trabajo. Lo principal es enfocarse en la tarea a realizar.
Resumen
Kanban vs. Scrum
Diferencias:
- Estructura:
- Kanban: Flujo continuo, sin roles fijos ni iteraciones definidas.
- Scrum: Iteraciones fijas (sprints) y roles específicos (Scrum Master, Product Owner).
- Visualización:
- Kanban: Tablero visual con columnas que representan el flujo de trabajo.
- Scrum: Tablero para gestionar el sprint, con elementos definidos en el backlog.
- Flexibilidad:
- Kanban: Alta flexibilidad en la priorización y adaptación del trabajo.
- Scrum: Cambios solo se realizan entre sprints.
Ventajas y Desventajas:
Kanban:
- Ventajas:
- Adaptabilidad rápida a cambios.
- Mejora continua del flujo de trabajo.
- Desventajas:
- Puede llevar a falta de enfoque si no se gestiona bien.
- Menos estructura puede ser confusa para algunos equipos.
Scrum:
- Ventajas:
- Fomenta la colaboración y la comunicación del equipo.
- Estructura clara con roles y eventos definidos.
- Desventajas:
- Menos flexible ante cambios durante el sprint.
- Puede ser complicado para equipos nuevos o menos experimentados.
Lenguajes de Programación en Ingeniería de Software
Debemos diferencia entre maquetar código y código en producción.
Maquetar Código:
- Definición: Es el proceso de diseñar y estructurar el código, normalmente en un entorno de desarrollo.
- Propósito: Permite crear prototipos, experimentar con ideas y ajustar el diseño antes de su implementación final.
- Características:
- Enfocado en la apariencia y funcionalidad inicial.
- Puede contener errores y ser inestable.
- Generalmente no está optimizado para el rendimiento.
Código en Producción:
- Definición: Es el código que está en uso en el entorno real, accesible para los usuarios finales.
- Propósito: Proporcionar una aplicación o servicio funcional y confiable.
- Características:
- Debe ser estable, seguro y optimizado.
- Requiere pruebas exhaustivas antes de su lanzamiento.
- Mantiene un monitoreo constante para detectar y corregir problemas.
Lenguajes
- Python: Librerías de código científico. Puede ser más lento que otras opciones. Destaca por su sencillez.
- R: Elegido por estadistas. Herramienta estadística. Adelantado en modelos.Importante para analistas.
- Scala: Spark se implementa sobre él. Usa Java de base. Con la implementación y optimización de PySpark bajó su necesidad. Interesante para programación funcional.
- Java: Potente lenguaje multiplataforma. Su escalabilidad es envidiable. Puede ser un cómodo siguiente paso.
- JavaScript: La navaja suiza para web developers. Súper flexible y útil para muchos ámbitos. Imponente por la cantidad de herramientas que tiene.Visualizaciones de datos más bellas posibles.
- C++ y derivados: Columna vertebral de muchos proyectos.Curva de aprendizaje potente.Muchas herramientas usan C en el fondo. Implementaciones modernas ayudan a que no sea tan difícil de implementar.
- Julia: Lenguaje de programación diseñado para la computación científica y numérica. Ofrece un alto rendimiento comparable al de C, pero con la simplicidad de Python. Ideal para tareas que requieren cálculos intensivos y procesamiento de datos. Su sintaxis es fácil de aprender y está ganando popularidad en la comunidad de ciencia de datos y aprendizaje automático. Además, cuenta con un ecosistema creciente de bibliotecas que facilitan el desarrollo en áreas como análisis de datos y modelado matemático.
Lo importante de los lenguajes. No es que los colecciones, sino que te sientas con comodidad implementando en diversos paradigmas de programación. Lo que vale es llevar tus ideas hasta generar valor.
¿Dónde y cómo escribir tu código?
- IDE.
- Editores de código.
- Notebooks.
La consola debe y tiene que ser tu amiga.
El dominio de Git es muy importante.
Automatización y scripting
Automatizar las tareas:
- Repetir una tarea
- Trabajar de manera inteligente
- Optimizar el proceso
- Utilizar recursos externos
Python es el rey del scripting dado:
- Lenguaje sencillo
- Librerías variadas
- Comunidad activa
- Multiplataforma
Prestar atención a no automatizar antes de tiempo y de esta forma evitamos que se automaticen cosas que no son repetitivas. (Aplicar la regla de Beetlejuice)
Fuentes de datos: SQL, NoSQL, API y web scraping
Utilidad de SQL: lenguaje de consulta, pero también el nombre con el que se identifican las bases de datos. Es excelente para transacciones por los principios ACID:
- Atomicity
- Consistency
- Isolation
- Durability
Las bases de datos NoSQL, son útiles para guardar objetos flexibles. La más famosa es MongoDB, Redis, ElasticSearch y HBase.
Por otra parte, la información que guardamos en estas bases de datos provienen de diversas fuentes las cuales accedemos por APIs o haciendo web scraping. Estos datos pueden venir de gobiernos, redes sociales, buscadores, noticias, empresas proveedoras de información, investigaciones, sitios en la red y otros.
API (Application Programming Interface)
- Consume información de otras plataformas.
- Permite utilizar capacidades mandando un input, recibiendo un output.
- Pueden ser creadas por uno, externas y de paga.
Web scraping
- Podemos emplear parsehub or Scrapy.
Diseño basado en modelos
Modelo de datos:
- Modelo de datos relacional.
- Modelos de datos semiestructurado.
- Modelos de datos entidad-relación.
- Modelo de datos basado en objetos.
Los modelos deben ser sostenibles.
Procesamiento de datos: pipelines, Apache Spark y cómputo paralelo
¿Qué es un pipeline de datos?
- Extraer: Archivos, Bases de datos (OLTP), Web scraping y API
- Transformar estos datos.
- Cargar: Data Warehouse (OLAP)
Apache Spark
Con Apache Spark se busca la velocidad, con un cache poderoso, un despliegue sencillo, trabajo en tiempo real, que sea políglota y escalable.
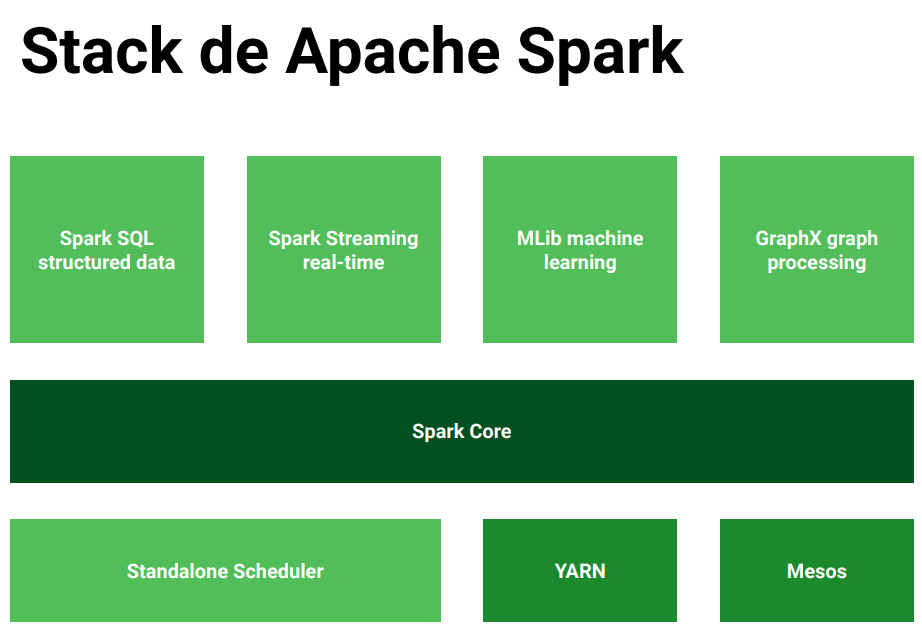
Permite el procesamiento en batch (lotes) y en stream (tiempo real). Apoyándose del procesamiento paralelo.
Automatizar los pipelines: Airflow
Para esto debemos tener 3 preguntas importantes:
- ¿Qué va a correr?
- ¿En qué secuencia?
- ¿Cuándo y cada cuánto va a correr?
El formato DAGs (Directed Acyclic Graphs) es como le hablamos a Airflow sobre la conexión de tareas, para secuenciar las tareas.
Con los DAGs:
- Definimos cuando se ejecuta la tarea, en cuanto a hora y fecha.
- Subdividir en tareas.
- Definimos la secuencia de la tareas
Containers y empaquetamiento: Docker y Kubernetes
El problema de los ambientes, en local funciona.
Empleando de Docker. Los contenedores aislan la estructura de los contenedores. Los orquestadores permiten el manejo de varios contenedores.
Manejo de ambientes para datos
La contribución debe ser ordenada. Las contribuciones deben seguir ciertas etapas bien definidas en modelo secuencial:
- Planeación
- Local
- Beta
- Producción
- En vivo
Esto puede variar según el equipo, empresa, y otros.
Testing de software y de datos
El testing es fundamental, es crucial. Tipos de testing de software:
- Manual Test
- E2E tests (UI Testing)
- Integration Tests
- Unit Test
CI/CD basico
CI/CD son prácticas fundamentales en el desarrollo de software que buscan automatizar y mejorar el proceso de entrega de aplicaciones. Aquí tienes un resumen básico:
CI (Integración Continua)
- Definición: Es la práctica de integrar cambios de código en un repositorio compartido de forma frecuente (varias veces al día).
- Objetivo: Detectar errores rápidamente y mejorar la calidad del software.
- Proceso:
- Los desarrolladores envían su código a un repositorio.
- Se ejecutan pruebas automáticas para verificar que el nuevo código no rompe la funcionalidad existente.
- Si las pruebas son exitosas, el código se integra al proyecto principal.
CD (Entrega Continua / Despliegue Continuo)
- Definición: Se refiere a la automatización de la entrega del código a producción (Entrega Continua) o a realizar despliegues automáticos (Despliegue Continuo).
- Objetivo: Facilitar lanzamientos frecuentes y reducir el tiempo entre el desarrollo y la disponibilidad del software para los usuarios.
- Proceso:
- En la Entrega Continua, el código se prepara para ser desplegado automáticamente, pero requiere una intervención manual para el lanzamiento.
- En el Despliegue Continuo, el código se despliega automáticamente en producción una vez que pasa las pruebas.
Beneficios de CI/CD
- Mayor calidad: Permite detectar errores de manera temprana.
- Rápida entrega: Acelera el ciclo de desarrollo y despliegue.
- Mejor colaboración: Fomenta la comunicación entre equipos de desarrollo y operaciones.
En resumen, CI/CD es un enfoque que ayuda a los equipos de software a entregar código de manera más eficiente y confiable.
La agilidad nos dice que queremos tener cosas útiles de manera continua, entragar valor entre diferentes tiempos. Existe una amplia variedad de herramientas.
Los flujos de datos son posibles con el manejo de ambientes.
DataOps y DevOps son enfoques que buscan mejorar la colaboración y la eficiencia en el desarrollo de software y la gestión de datos, pero se enfocan en diferentes aspectos. Aquí te presento un análisis de sus diferencias y límites:
Definiciones
DevOps: Es una práctica que integra el desarrollo de software (Dev) y las operaciones de TI (Ops) para mejorar la colaboración entre equipos, automatizar procesos, y acelerar la entrega de software. Su objetivo es fomentar una cultura de responsabilidad compartida y mejorar la calidad del software.
DataOps: Se centra en la gestión de datos, buscando aplicar principios similares a los de DevOps en el ámbito de los datos. DataOps busca mejorar la calidad de los datos, acelerar el ciclo de vida de los datos y garantizar que los datos sean accesibles y útiles para los usuarios y aplicaciones.
Diferencias Clave
- Enfoque:
- DevOps se enfoca en el ciclo de vida del desarrollo de software.
- DataOps se enfoca en la gestión y el flujo de datos.
- Cultura:
- DevOps promueve la colaboración entre desarrolladores y operaciones.
- DataOps promueve la colaboración entre científicos de datos, ingenieros de datos y equipos de negocio.
- Herramientas y Tecnologías:
- DevOps utiliza herramientas como CI/CD, contenedores y monitoreo de aplicaciones.
- DataOps utiliza herramientas para la integración de datos, calidad de datos y automatización de flujos de trabajo de datos.
Límites y Convergencias
Interacción: Aunque se centran en áreas distintas, DevOps y DataOps pueden beneficiarse mutuamente. Por ejemplo, un entorno de DevOps puede facilitar el acceso y el despliegue de modelos de datos desarrollados bajo DataOps.
Automatización: Ambos enfoques enfatizan la automatización, aunque en diferentes contextos. DevOps automatiza pruebas y despliegues, mientras que DataOps automatiza la integración y la calidad de los datos.
Agilidad: Ambos buscan mejorar la agilidad. DevOps acelera el desarrollo de software, mientras que DataOps agiliza la entrega y el uso de datos.
El límite entre DataOps y DevOps es difuso, ya que ambos buscan mejorar la eficiencia y la colaboración. La clave está en reconocer que, aunque tienen enfoques diferentes, pueden coexistir y complementarse para ofrecer un ciclo de vida de desarrollo y datos más integrado y eficiente. Implementar ambos enfoques en una organización puede llevar a una mejor toma de decisiones y a un uso más efectivo de los recursos.
Servidores y computación en la nube para data
El nube es una serie de computadores interconectados. Las más comunes son AWS, Azure y Google Cloud.
Trabajo con servidores en una red privada, también puede ser común.
- Mantener recursos de acuerdo a las necesidades.
- Control sobre los usuarios, con el objetivo de siempre limitar su poder sobre los servicios.
- Reducir los costos, fundamentalmente distribuyendo las cargas, además de mantener la seguridad.
Reentrenamiento y control de salud de servicios
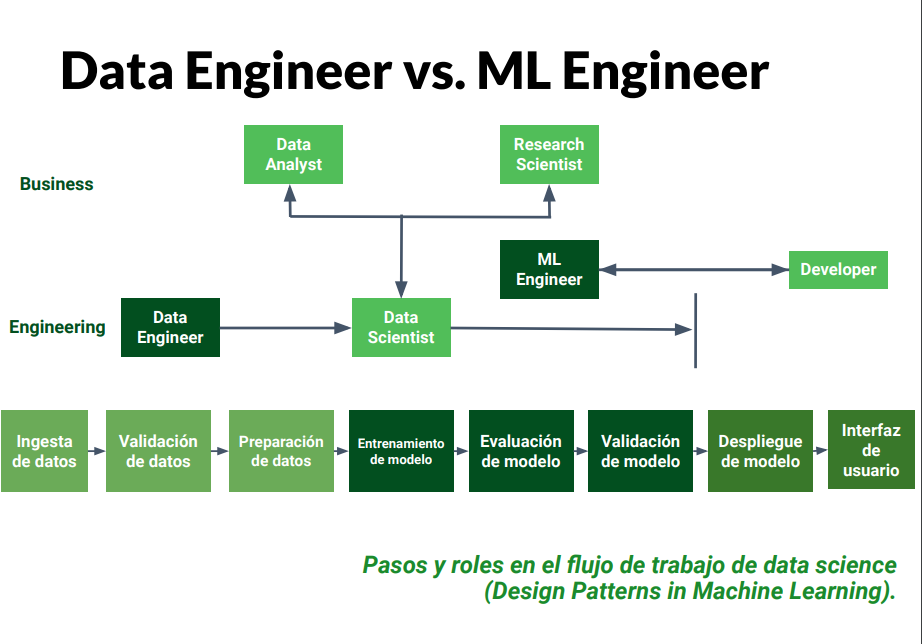
Los modelos de Machine Learning tienen que tener actualizaciones regularmente. Debido a que pierde efectividad naturalmente. Por tanto se deben emplear la llegada de datos nuevos para entrenar nuevemanente el modelo.
Medición de indicadores y seguimiento a proyectos
El monitoreo es esencial en nuestros proyectos. Pues conociendo los puntos de riesgos podemos monitorearlos, y otorgarles visibilidad mediante dashboards, alertas y notificaciones.
Ejerciendo y Buscando Oportunidades como Data Engineer
Se debe preparar el LinkedIn. Conectar estableciendo contacto físico y virtual. Buscar en sitios de posteos de posiciones de trabajo. Es fundamental aprender English.
Evolución en el rol: ganando seniority como Data Engineer
- Primer día: aprende
- Primer mes: contribuye
- Primer año: mentorea
No tengas miedo de ir por más.
Evolución en el rol: manager, architect, pivot
Dos caminos: técnico y administrativo
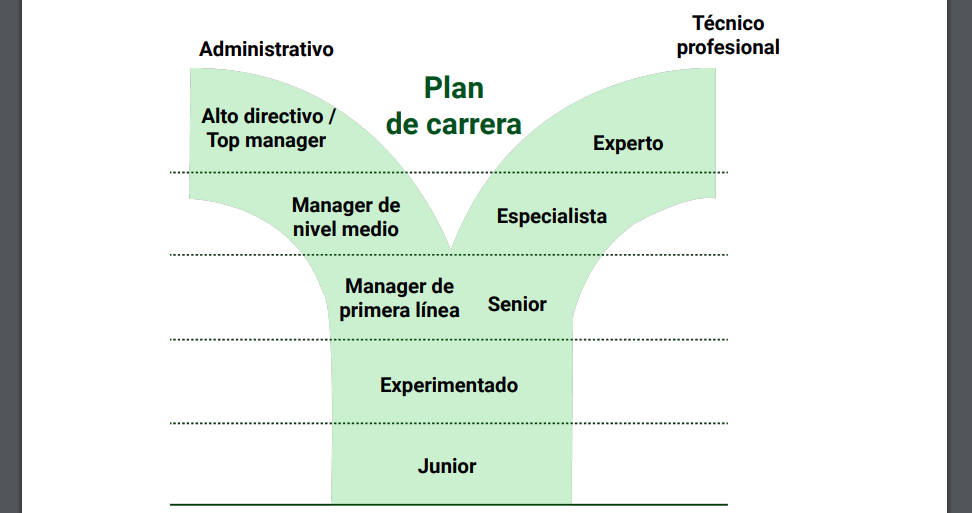
Pero podemos cambiar a otro rol:
- Arquitectura
- Ciencia de datos
- DevOPs y cloud
Trabajando en equipo como Data Engineer
Se debe recordar tu posición en el equipo. Establece como meta la colaboración con personas en otros roles como:
- Data scientist y analysts.
- Otras data engineers.
- Personas de producto.
- Equipo de desarrollo de aplicaciones.
Antes de ser data engineer
- Conoce la comunidad.
- Practica y crea proyectos.
- Comparte tus procesos y resultados.
Ya siendo data engineer
- Ser parte activa de la comunidad.
- Exponer tus resultados.
- Mentorear a otras personas.
- Contribuir a los proyectos de código abierto.
Atención
Este tutorial es basado en el Curso de Fundamentos de Ingeniería de Datos de Platzi.